I'm trying to create a distributed spark cluster on kubernetes. for this, I've created a kubernetes cluster and on top of it i'm trying to create a spark cluster. My docker file is
# Copyright (c) Jupyter Development Team.
# Distributed under the terms of the Modified BSD License
ARG BASE_CONTAINER=jupyter/scipy-notebook
FROM $BASE_CONTAINER
LABEL maintainer="Jupyter Project <jupyter@googlegroups.com>"
USER root
# Spark dependencies
ENV SPARK_VERSION 2.3.2
ENV SPARK_HADOOP_PROFILE 2.7
ENV SPARK_SRC_URL https://www.apache.org/dist/spark/spark-$SPARK_VERSION/spark-${SPARK_VERSION}-bin-hadoop${SPARK_HADOOP_PROFILE}.tgz
ENV SPARK_HOME=/opt/spark
ENV PATH $PATH:$SPARK_HOME/bin
RUN apt-get update && \
apt-get install -y openjdk-8-jdk-headless \
postgresql && \
rm -rf /var/lib/apt/lists/*
ENV JAVA_HOME /usr/lib/jvm/java-8-openjdk-amd64/
ENV PATH $PATH:$JAVA_HOME/bin
RUN wget ${SPARK_SRC_URL}
RUN tar -xzf spark-${SPARK_VERSION}-bin-hadoop${SPARK_HADOOP_PROFILE}.tgz
RUN mv spark-${SPARK_VERSION}-bin-hadoop${SPARK_HADOOP_PROFILE} /opt/spark
RUN rm -f spark-${SPARK_VERSION}-bin-hadoop${SPARK_HADOOP_PROFILE}.tgz
USER $NB_UID
ENV POST_URL https://jdbc.postgresql.org/download/postgresql-42.2.5.jar
RUN wget ${POST_URL}
RUN mv postgresql-42.2.5.jar $SPARK_HOME/jars
# Install pyarrow
RUN conda install --quiet -y 'pyarrow' && \
conda install pyspark==2.3.2 && \
conda clean -tipsy && \
fix-permissions $CONDA_DIR && \
fix-permissions /home/$NB_USER
USER root
ADD log4j.properties /opt/spark/conf/log4j.properties
ADD start-common.sh start-worker.sh start-master.sh /
ADD loop.sh $SPARK_HOME/bin/
ADD core-site.xml /opt/spark/conf/core-site.xml
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
RUN chmod +x $SPARK_HOME/bin/loop.sh
RUN chmod +x /start-master.sh
RUN chmod +x /start-common.sh
RUN chmod +x /start-worker.sh
ENV PATH $PATH:/opt/spark/bin/loop.sh
RUN apt-get update
RUN apt-get install curl -y
WORKDIR /
and my master and worker yaml files are
kind: ReplicationController
apiVersion: v1
metadata:
name: spark-master-controller
spec:
replicas: 1
selector:
component: spark-master
template:
metadata:
labels:
component: spark-master
spec:
hostname: spark-master
containers:
- name: spark-master
image: hrafiq/dockerhub:spark-jovyan-local
command: ["sh", "/start-master.sh", "run"]
imagePullPolicy: Always
ports:
- containerPort: 7077
hostPort: 7077
- containerPort: 8080
hostPort: 8080
- containerPort: 6066
hostPort: 6066
- containerPort: 7001
hostPort: 7001
- containerPort: 7002
hostPort: 7002
- containerPort: 7003
hostPort: 7003
- containerPort: 7004
hostPort: 7004
- containerPort: 7005
hostPort: 7005
- containerPort: 4040
hostPort: 4040
env:
- name: SPARK_PUBLIC_DNS
value: 192.168.1.254
- name: SPARK_MASTER_IP
value: 192.168.1.254
And worker file
kind: ReplicationController
apiVersion: v1
metadata:
name: spark-worker-controller
spec:
replicas: 2
selector:
component: spark-worker
template:
metadata:
labels:
component: spark-worker
spec:
containers:
- name: spark-worker
image: hrafiq/dockerhub:spark-jovyan-local
command: ["sh", "/start-worker.sh","run"]
imagePullPolicy: Always
ports:
- containerPort: 8081
- containerPort: 7012
- containerPort: 7013
- containerPort: 7014
- containerPort: 5001
- containerPort: 5003
- containerPort: 8881
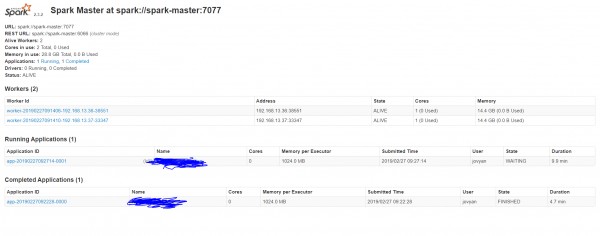
Workers get registered with master but still unable to execute any tasks, no cores are assigned to executors and no job executes. This error is displayed
"Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources"
this is the spark UI