A stacked LSTM model consists of multiple LSTM layers stacked on top of each other to capture both short-term and long-term dependencies in a sequence. For text generation, this model can be trained on a dataset of text and then used to generate new text sequences based on a given prompt.
Here are the steps you can follow to build it:
- Install Required Libraries
- First, ensure you have TensorFlow installed (which includes Keras).
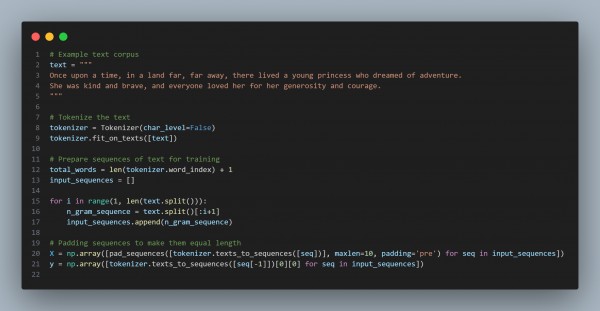
- Prepare Your Dataset
- You need a large corpus of text data to train the model. Here's an example of preparing a small dataset:
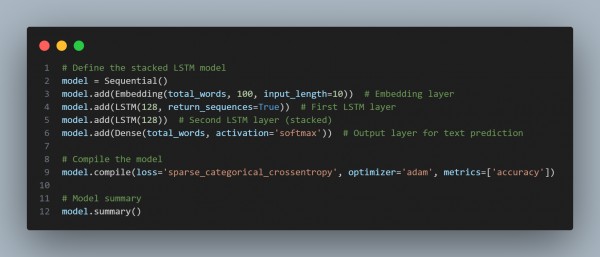
- Build the Stacked LSTM Model
- Now, build a stacked LSTM model using Keras.
- Train the Model
- Train the model on your dataset. You can adjust the number of epochs based on your dataset size.
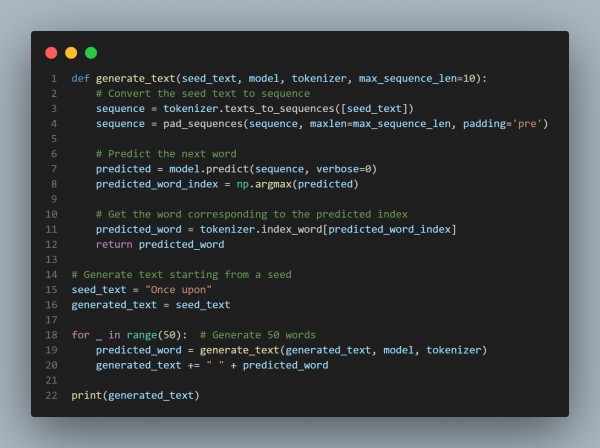
- Text Generation
- After training the model, use it to generate text. Here's how you can generate the next word based on a seed sequence:
- Final Notes
- Training: In practice, you'll want to train on a larger dataset and tune hyperparameters like the LSTM units, number of epochs, and batch size.
- Text Generation: The generated text can be improved with better preprocessing, larger datasets, and fine-tuned models.
Here are the code snippets showing all those steps:

In the above code, we are using the following:
- Prepare Data: Tokenize and prepare sequences of text for model training.
- Build Model: Create a stacked LSTM model with multiple LSTM layers.
- Train Model: Train the model on the prepared text data.
- Generate Text: Use the trained model to predict the next word and generate new text sequences.
Hence, by referring to the above, you can build a stacked LSTM model in Keras for text generation.


























